Curso: Introducción a Ciencia de Datos (CS351)
Profesor: Dr. Erick Gomez Nieto
Semestre: 2022–1
La victimización de empresas es un problema latente en la sociedad peruana, día a día escuchamos en los medios de comunicación noticias de robos y asaltos a establecimientos comerciales. Si bien la capital Lima tiene un mayor número de incidencias, los demás departamentos no son ajenos a este problema social. De hecho, un estudio realizado por el INEI en el año 2018 demostró qué, durante setiembre del 2017 y agosto del 2018, 28 de cada 100 empresas fueron víctimas de al menos un hecho delictivo.
La violencia impacta en el crecimiento económico del país, no sólo afecta directamente a la población económicamente activa, sino que disminuye los incentivos directos para invertir, así como los incentivos gubernamentales que se desvían para reforzar políticas de seguridad y control. Motivado por este contexto, se realizó un estudio de ciencia de datos sobre la victimización de empresas peruanas, intentando modelar su comportamiento para poder predecir el número de delitos que podrían ocurrir durante el año 2022.
Para abordar este proyecto se elaboró una solución basada en ciencia de datos, desde el proceso de recolección de datos, hasta el modelamiento temporal de los eventos de victimización. Sin mayor preámbulo, repasemos cada una de estas etapas.
Recolección de datos
Se consideró el uso de los datos abiertos que ofrece el INEI, sin embargo, estos ocultaban mucha información por cuestiones de privacidad. Entonces, ¿Cómo recolectar la información necesaria? La respuesta es clara, hacer web scraping a páginas web de noticias. Si bien existen muchos medios, como las redes sociales, los periódicos se caracterizan por tener un mayor grado de credibilidad y confianza al ser entidades que dependen de su buena reputación y aceptación de los lectores. Luego de revisar varios diarios en linea, se decidió hacer web scraping al sitio web del diario Correo.
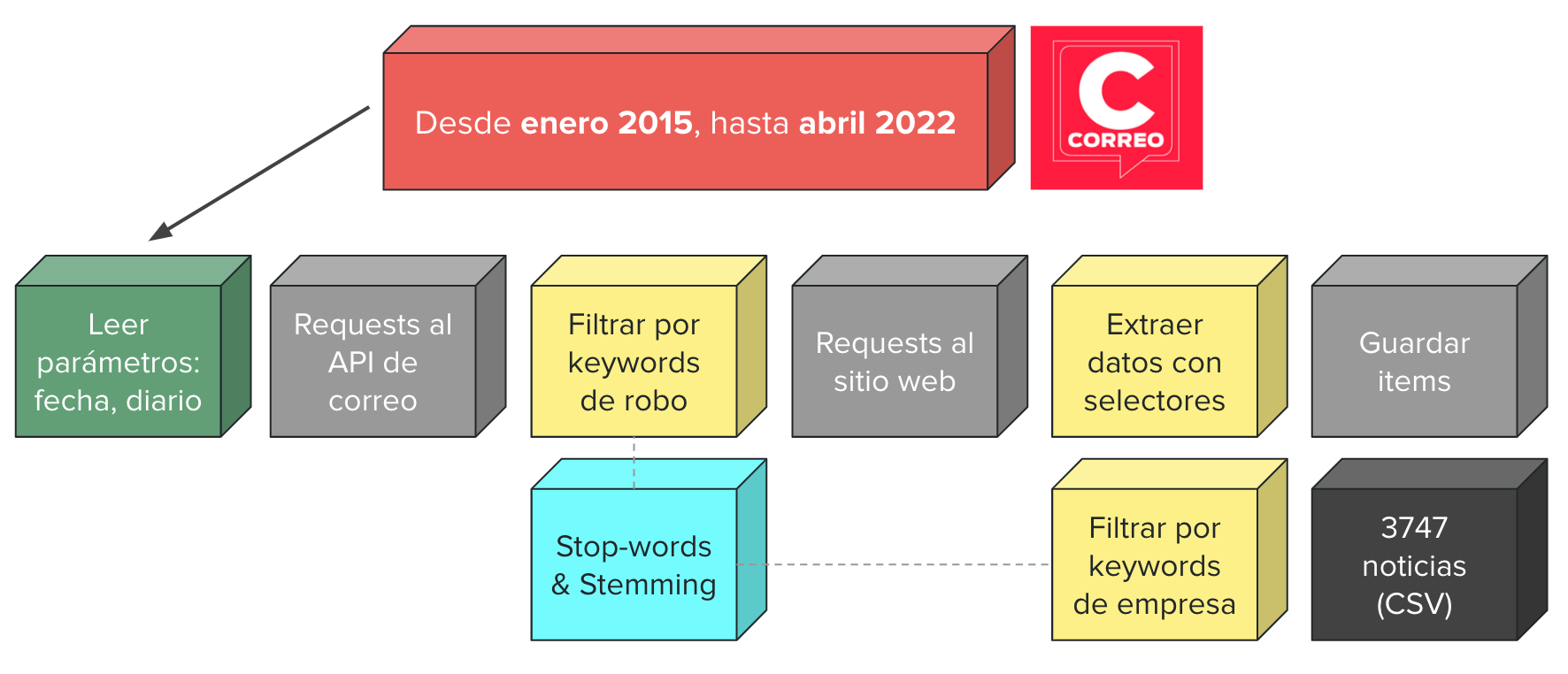
El spider se programó en Python haciendo uso del framweork Scrapy. El pipeline seguido fue el siguiente:
-
Primero se leen los parámetros de ejecución, las fechas de recolección de noticias van desde enero del 2015 a abril del 2022.
-
Luego, se mandan de forma concurrente requests al API de Correo preguntando por los posts durante ese rango de tiempo.
-
Una vez obtenidos los responses, se realiza un filtro por keywords de victimización, e.g. robo, asalto, ladrones, etc. Para realizar el match se eliminan los stop words del texto y se aplica stemming para eliminar ambigüedades léxicas.
-
Ahora que tenemos noticias sobre victimización, debemos realizar un filtro adicional, encontrar aquellas que hablen sobre empresas. Para ello, los requests ya no se dirigen al API, ahora se envían al sitio web donde se encuentra la redacción completa de la noticia.
-
El proceso de filtrado es similar al anterior, ahora se buscan keywords relacionadas a empresas, e.g. negocio, comercio, joyería, etc. Una vez filtradas las noticias, se guardan los campos más importantes usando selectores. Los campos guardados por cada noticia fueron: url, date, title, summary, body y score. Este último campo indica qué tan seguro es que dicha noticia efectivamente se trate de la victimización a una empresa.
-
Finalmente, todos los items son exportados en formato CSV. Con el método propuesto se lograron recopilar 3747 noticias.
Preparación de datos
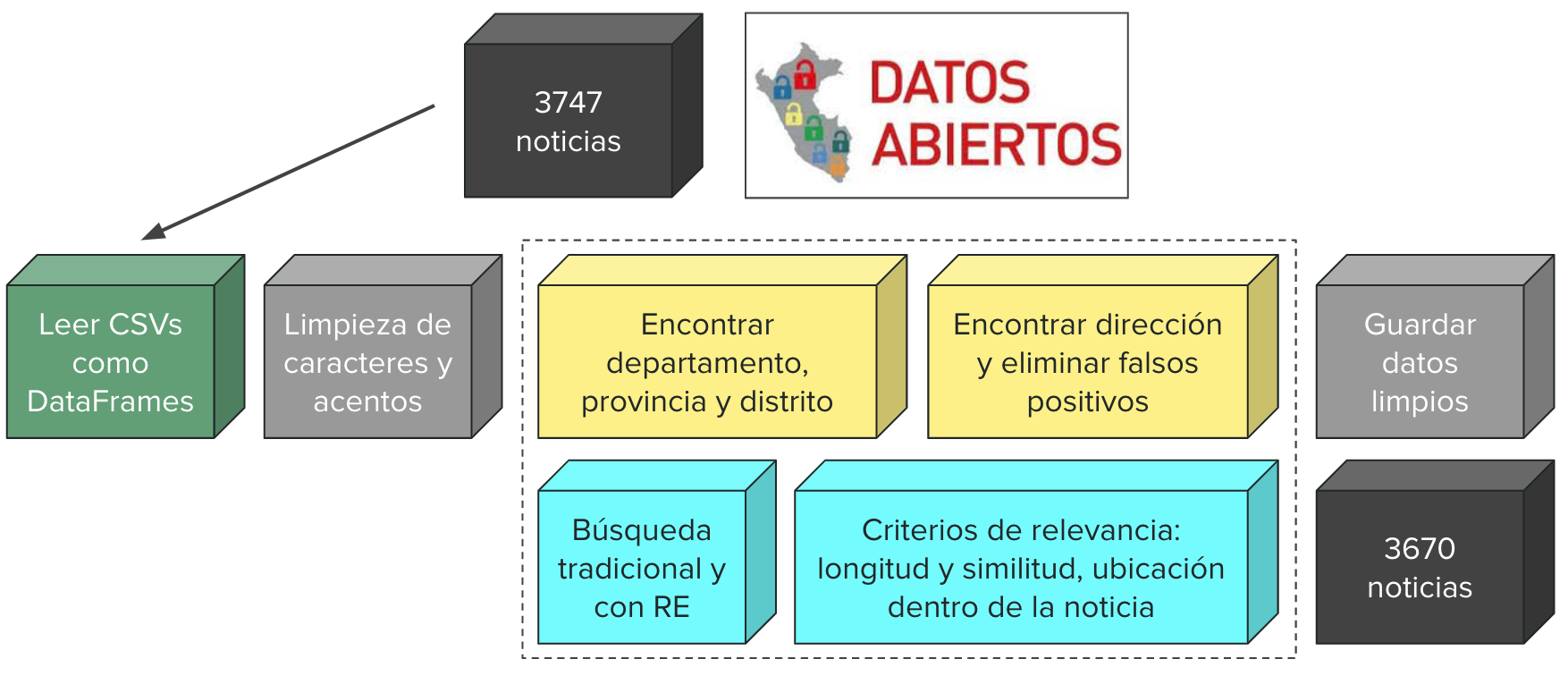
En esta etapa del proyecto se añaden campos de geo-localización a los datos: latitude, longitude y location. Para ello, se realizaron los siguientes pasos:
-
Se lee el archivo CSV obtenido mediante web scraping usando la librería pandas, por ende, los datos se representan como un DataFrame. Adicionalmente, para encontrar la ubicación de las noticias, se utilizó la siguiente base de datos que contiene la información de todos los distritos de Perú.
-
Una vez cargadas las noticias, se hace la limpieza de su contenido. Se eliminan caracteres especiales, acentos, y el texto se convierte a minúsculas.
-
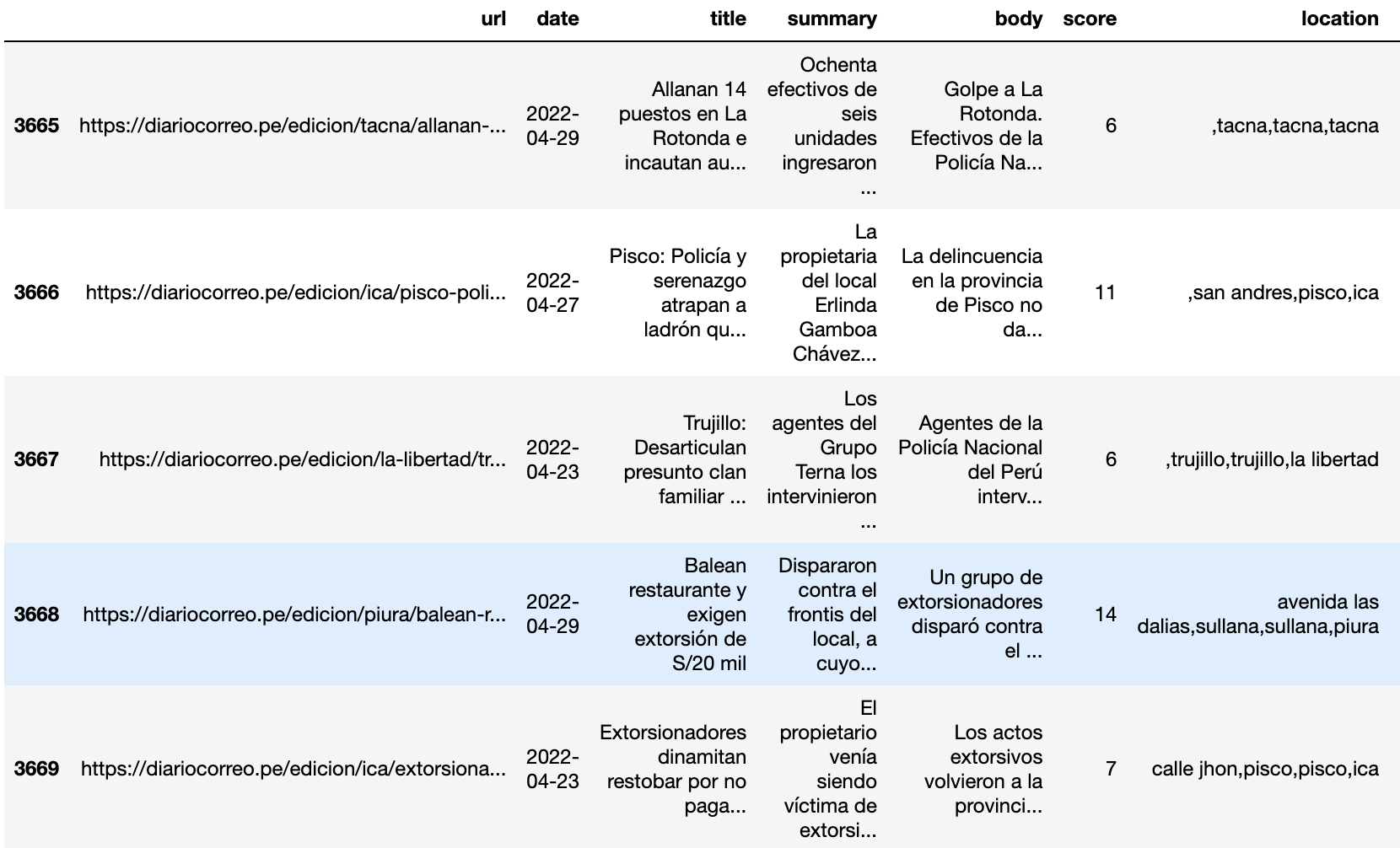
Para encontrar la ubicación dentro del texto de las noticias, se tuvo que hacer búsquedas exactas de los distritos, provincias y departamentos en determinado orden. Las url de algunas noticias tienen presente el departamento, reduciendo el campo de búsqueda. Se tomaron otros criterios para verificar la ubicación, por ejemplo, si el nombre de un distrito está presente en la noticia y es diferente al nombre de la provincia, entonces tiene mayor relevancia. Otro criterio es la ubicación dentro de la noticia, si el lugar está presente en el título tiene mayor relevancia que un lugar dentro del cuerpo. Los resultados fueron muy alentadores, con pocos falsos positivos, aquí un ejemplo del campo resultante:
-
Una vez encontrada la locación, se pasó dicho valor al geo-localizador de geopy para encontrar la longitud y latitud de las noticias.
from geopy.geocoders import Nominatim geolocator = Nominatim() def find_coordinates(row): loc = geolocator.geocode(row["location"]) return loc.latitude, loc.longitude data[["latitude", "longitude"]] = data.apply( lambda row: find_coordinates(row), axis=1, result_type="expand" ) -
Finalmente, se guardan los datos limpios y geo-localizados, logrando obtener 3670 noticias. Aquellas que no obtuvieron una ubicación fueron eliminadas de la base de datos.
Visualización y exploración de datos
Durante esta etapa se extraen insights de los datos, la primera visualización realizada fue la frecuencia de crímenes por departamento, como era de esperar, las regiones con mayor población presentan un mayor número de ocurrencias.
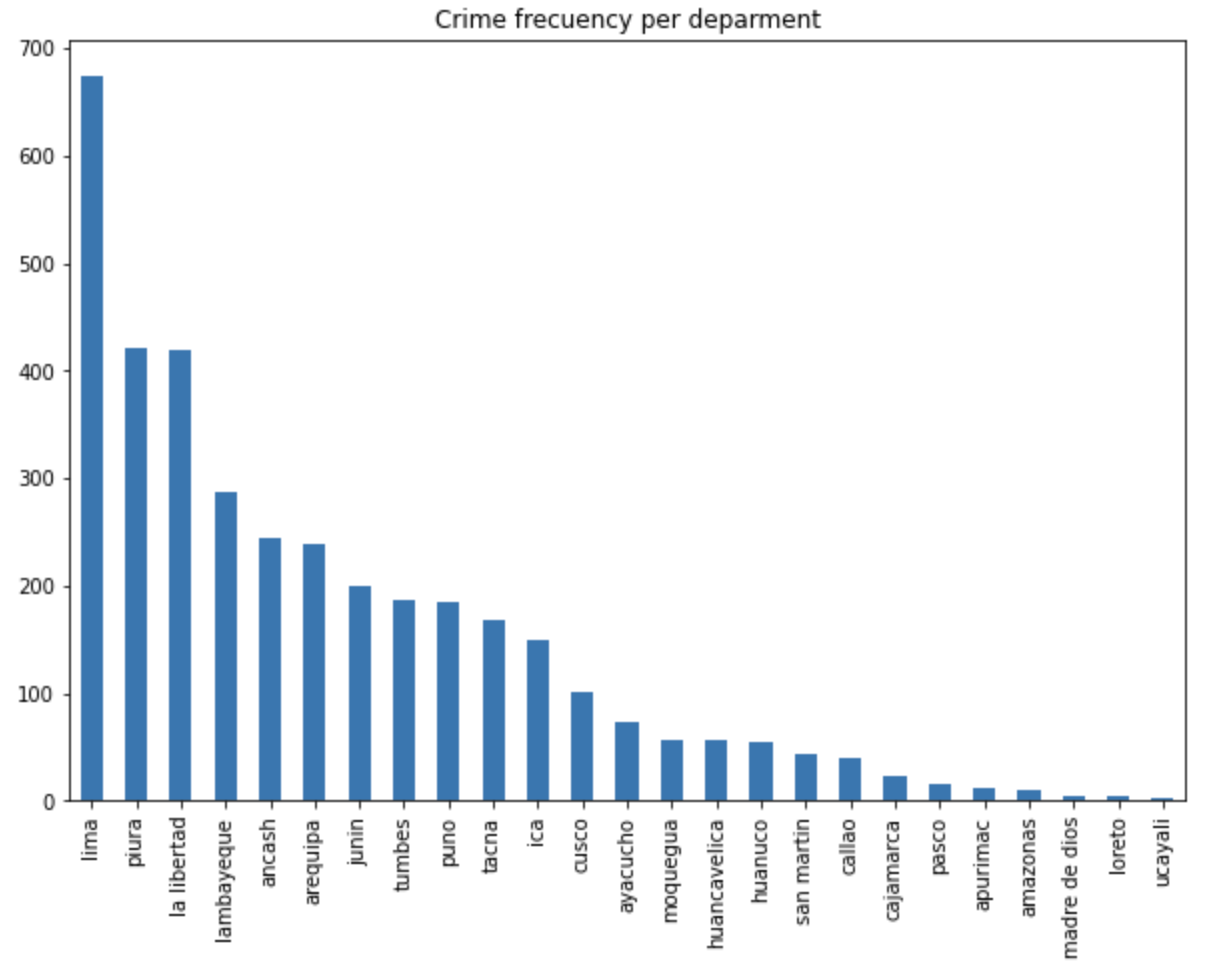
Sin embargo, estas cifras no reflejan el nivel de inseguridad de cada departamento. El ratio de victimización por cantidad de habitantes presenta una mejor visualización de las incidencias criminales. Para ello, se consiguió una base de datos con la población de cada distrito del Perú, haciendo la división correspondiente, obtenemos los siguientes valores.
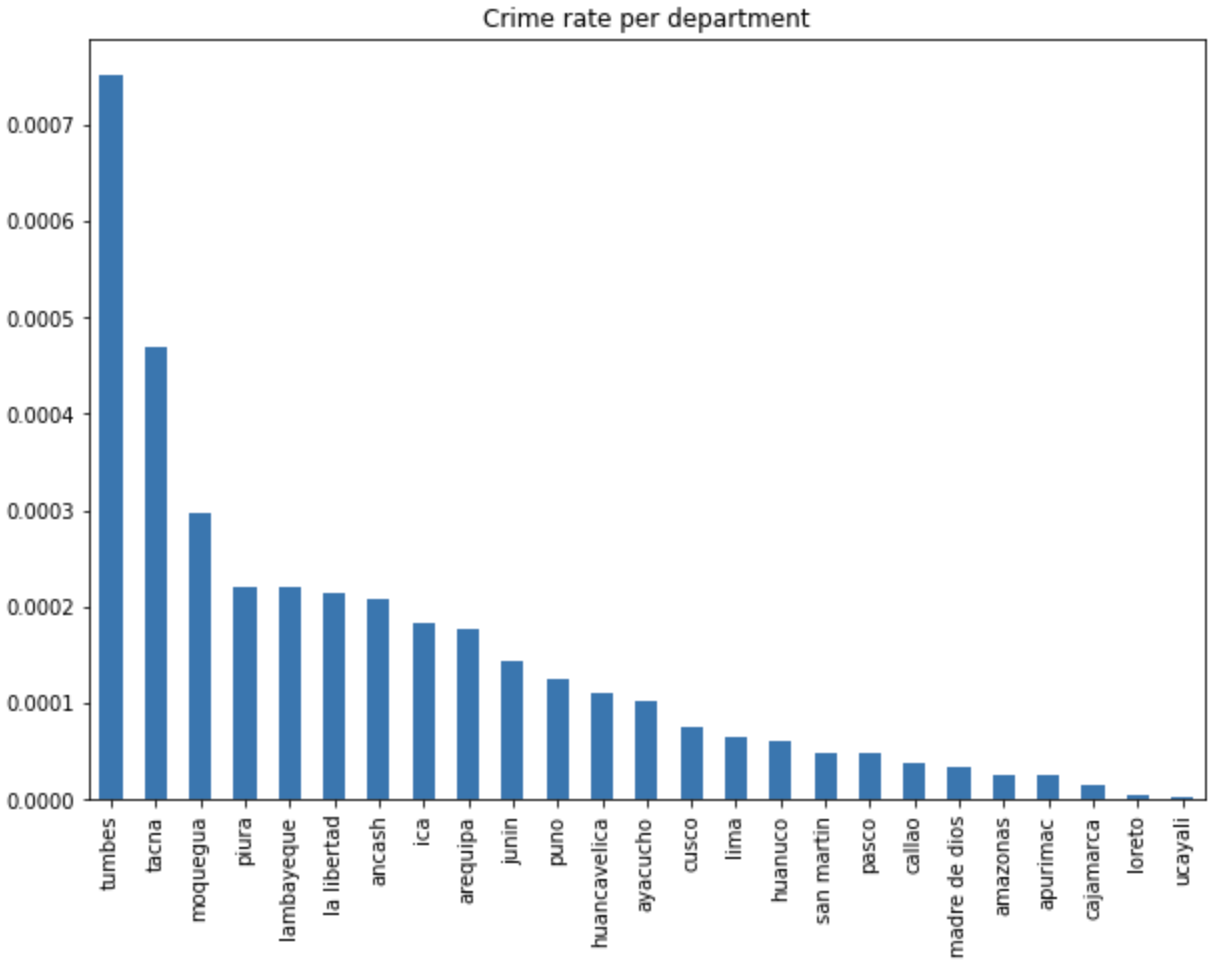
Algunos departamentos mantienen sus posiciones, y algunos cambian considerablemente. Gracias al gráfico de barras, podemos determinar que Tumbes, Tacna, Moquegua, Piura y Lambayeque son las cinco regiones cuyas empresas sufren de un mayor grado de victimización por número de habitantes durante los últimos 7 años.
Otro gráfico interesante es el número de hechos delictivos por mes. La frecuencia de crimen por unidad de tiempo puede apreciarse en la siguiente visualización.
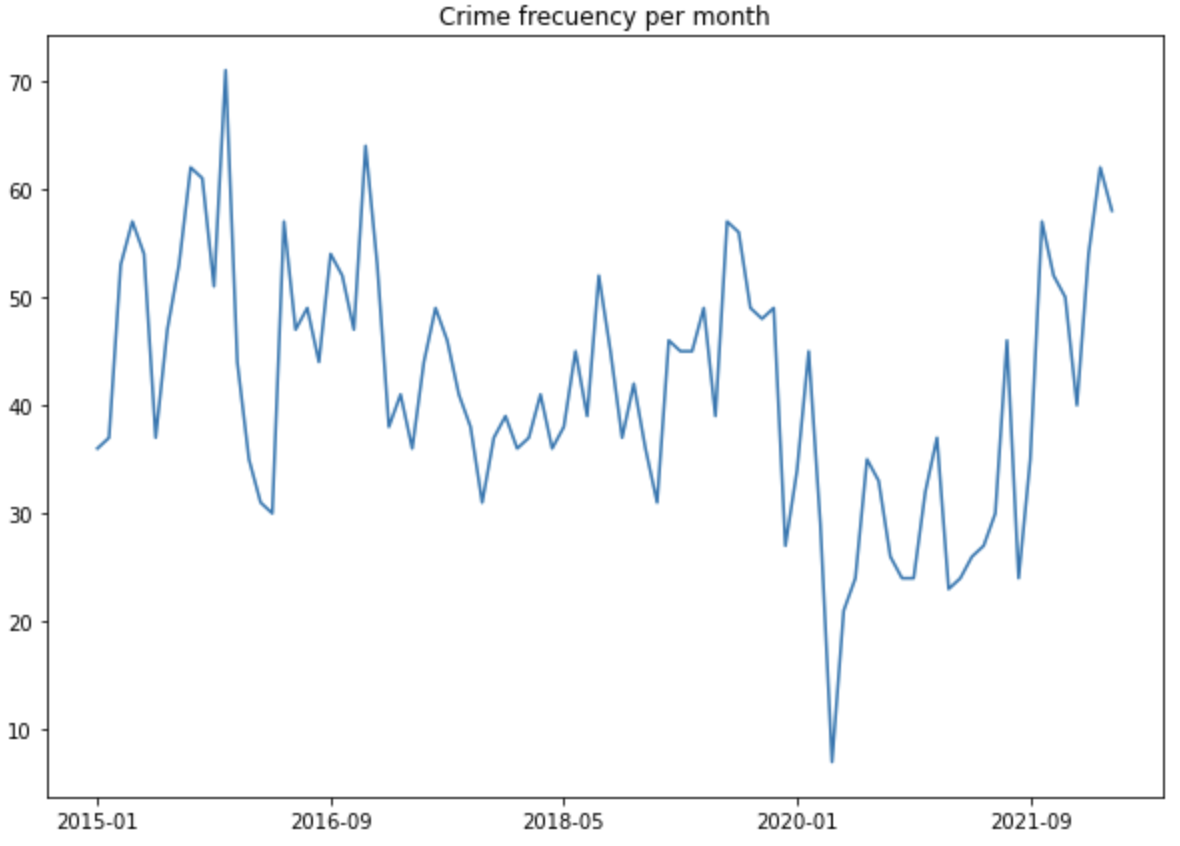
Estos datos indican cierta estacionalidad anual en los datos, además, los meses de abril, julio y noviembre presentan los picos más altos. Un hecho interesante es la reducción considerable de crimen tras la declaración de cuarentena en marzo del 2020. No obstante, durante el año 2021 y lo que va del 2022 los valores retoman su comportamiento pre-pandemia.
Los wordclouds y bag of words son modelos que representan la frecuencia de palabras de forma visual y numérica respectivamente. El modelo de wordcloud toma en cuenta las ocurrencias en todo el corpus, sin embargo, en bag of words se considera la ocurrencia por documento, ponderando la relevancia de cada palabra en el corpus. Podemos apreciar ambos modelos a continuación, al tratarse de noticias sobre victimización a empresas, es natural que las palabras mas comunes sean “soles”, “dinero”, “tienda” o “empresa”.
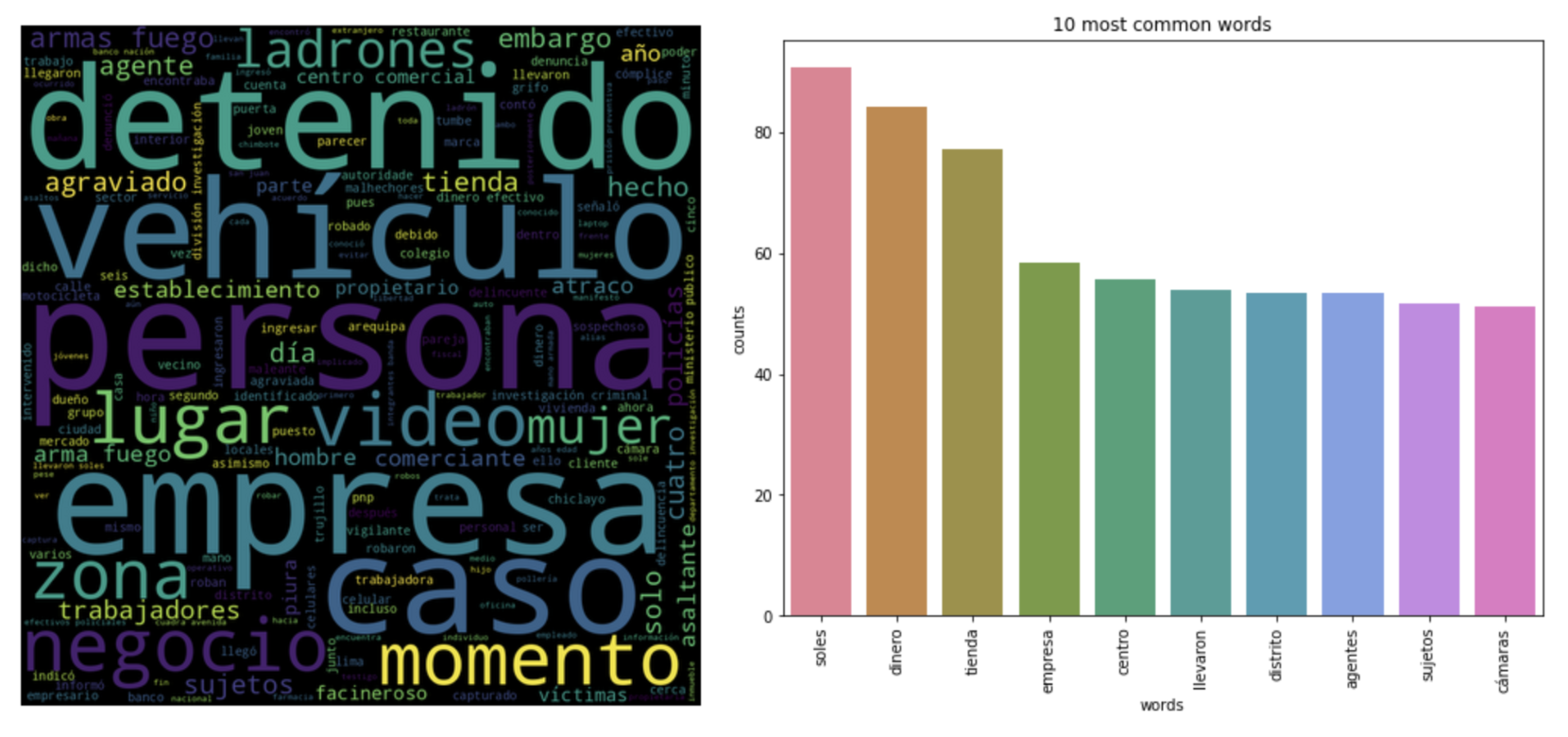
De la mano con la frecuencia de las palabras, se puede aplicar el modelo de Latent Dirichlet Allocation para encontrar los tópicos más comunes dentro del corpus. Básicamente, un tópico representa el tema de un grupo de noticias, dividiendo el corpus en n grupos. En esta ocasión, se calcularon 5 tópicos (grupos) y las 5 palabras que representan a cada tópico.
count_vectorizer = CountVectorizer()
count_data = count_vectorizer.fit_transform(data["normalized_text"])
number_topics = 5
number_words = 5
lda = LatentDirichletAllocation(n_components=number_topics)
lda.fit(count_data)
print_topics(lda, count_vectorizer, number_words)
# Topic 0: comisaría, agentes, lugar, policial, mujer
# Topic 1: banda, penal, criminal, investigación, fiscalía
# Topic 2: dinero, arma, fuego, soles, delincuente
# Topic 3: tienda, agentes, celulares, comercial, robar
# Topic 4: extorsionadores, empresa, extorsión, soles, trujillo
Por último, se realizó una visualización geográfica utilizando folium y los datos de latitud y longitud obtenidos durante la preparación de datos. Se construyó un heatmap haciendo uso de los plugins de folium. La visualización refleja las cifras encontradas por departamento. Donde las ciudades mas importantes tienen un mayor número de marcadores. Puede acceder a la visualización interactiva y descubrir los lugares con altos niveles de victimización de empresas y las noticias relacionadas.
Modelamiento
El objetivo del proyecto es la predicción de la cantidad de crímenes que podrían ocurrir en nuestro país durante los meses de mayo del 2022 a diciembre del 2022. Ya que se trata de una serie temporal, se decidió utilizar el modelo ARIMA.
Para ajustar mejor el modelo, se consideró el uso de una variable exógena que determine el comportamiento de la serie. Para ello, se entrenó el modelo con dos bases de datos: el PBI mensual y la tasa de desempleo mensual. Se eligieron dichas variables debido a que, si la tasa de desempleo aumenta, es muy probable que la tasa de crimen también lo haga. De igual manera, si el PBI disminuye, la tasa de crimen podría aumentar.
El modelo ARIMA requiere de la definición de tres parámetros:
- orden: (p, d, q).
- variable exógena: desempleo o PBI.
- orden estacionario: (P, D, Q, m).
Para encontrar los valores óptimos se ejecutó el método de Cross Validation y las gráficas de diferenciación, auto-correlación y auto-correlación parcial. Una vez encontrados dichos valores, se entrenó el modelo con los datos de entrenamiento.
# Mejores valores obtenidos por Cross Validation
best_order = (2,1,0)
best_exog = "unemployment"
best_seasonal_order = (1,0,0,12)
# Construcción del modelo
best_model = ARIMA(
train_data["count"],
exog=train_data[best_exog],
order=best_order,
seasonal_order=best_seasonal_order
)
best_model_fit = best_model.fit()
Una vez ajustado el modelo, se pudo realizar el forecasting de los meses siguientes. Los datos de prueba son los primeros 4 meses del 2022. Si graficamos los datos actuales y los valores conseguidos por el modelo, observamos que la coincidencia es alta.
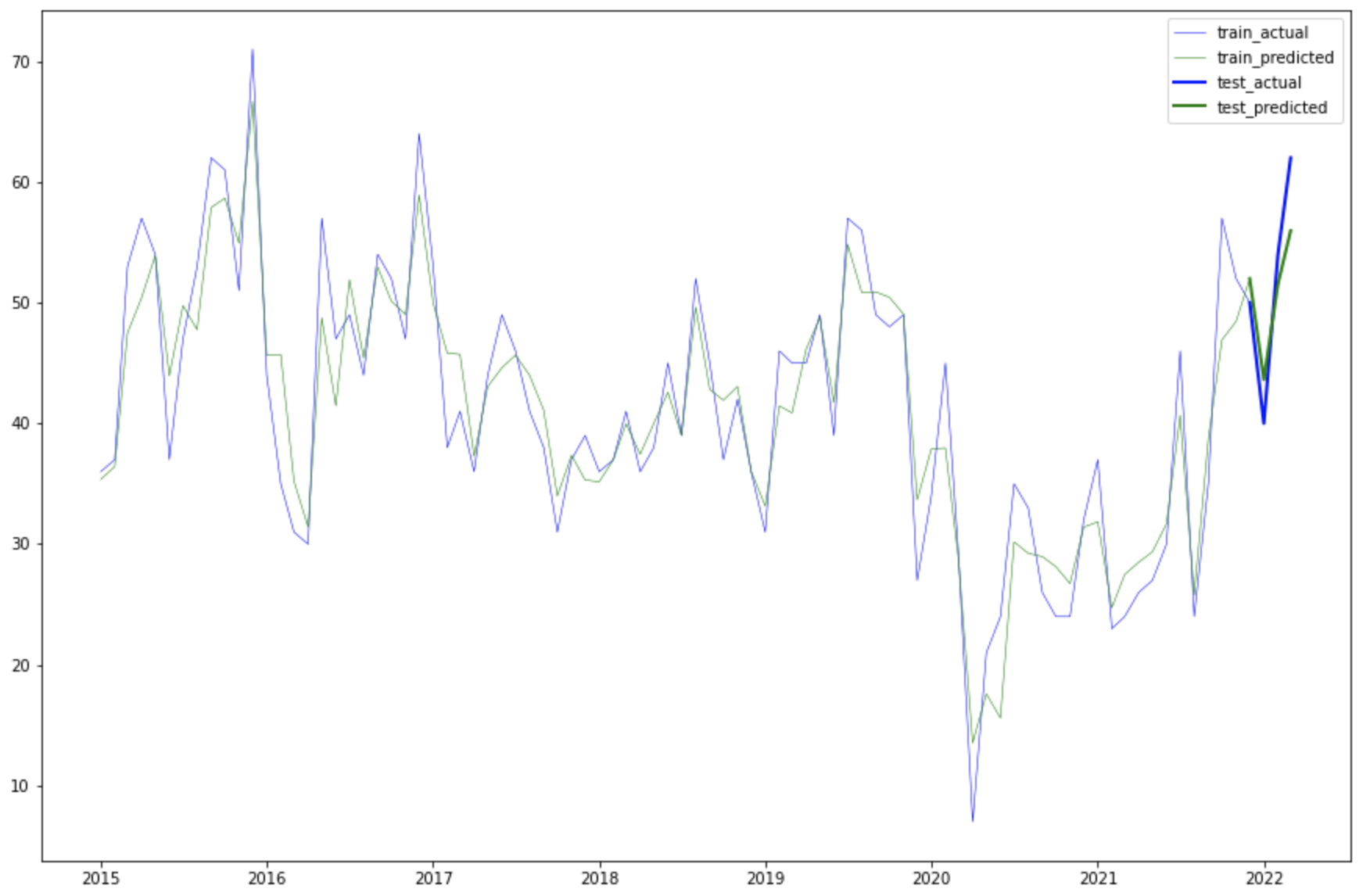
Se calculó el error cuadrado medio luego de aplicar el modelo a los datos de prueba. Dicho valor debe acercarse a cero y nos indica qué tan bien se pudo modelar el comportamiento temporal de la serie.
total_score = mean_squared_error(
final_df["count"], final_df["predicted"]
)
print(total_score)
# 22.26480087584455
Elaborando predicciones
Ahora que tenemos el modelo que configura el número de crímenes a empresas en Perú, podemos predecir cuántos crímenes podrían ocurrir en los próximos meses. Para ello, necesitamos predecir primero la tasa de desempleo con los datos actuales, ya que dichos valores representan la variable exógena del modelo principal.
Se utilizó también ARIMA para modelar el comportamiento de la tasa de desempleo, utilizando las gráficas de auto-correlación y diferenciación, se definieron los valores de los parámetros y se construyó el siguiente modelo.
# Construcción del modelo
unemployment_model = ARIMA(
unemployment_serie, order=(1,1,1), seasonal_order=(1,1,0,12)
)
unemployment_model_fit = unemployment_model.fit()
# Forecasting
fc = unemployment_model_fit.forecast(steps=8, alpha=0.05)
Aplicando el método forecast, se obtuvieron los siguientes valores que predicen la tasa de desempleo hasta el mes de diciembre del 2022.
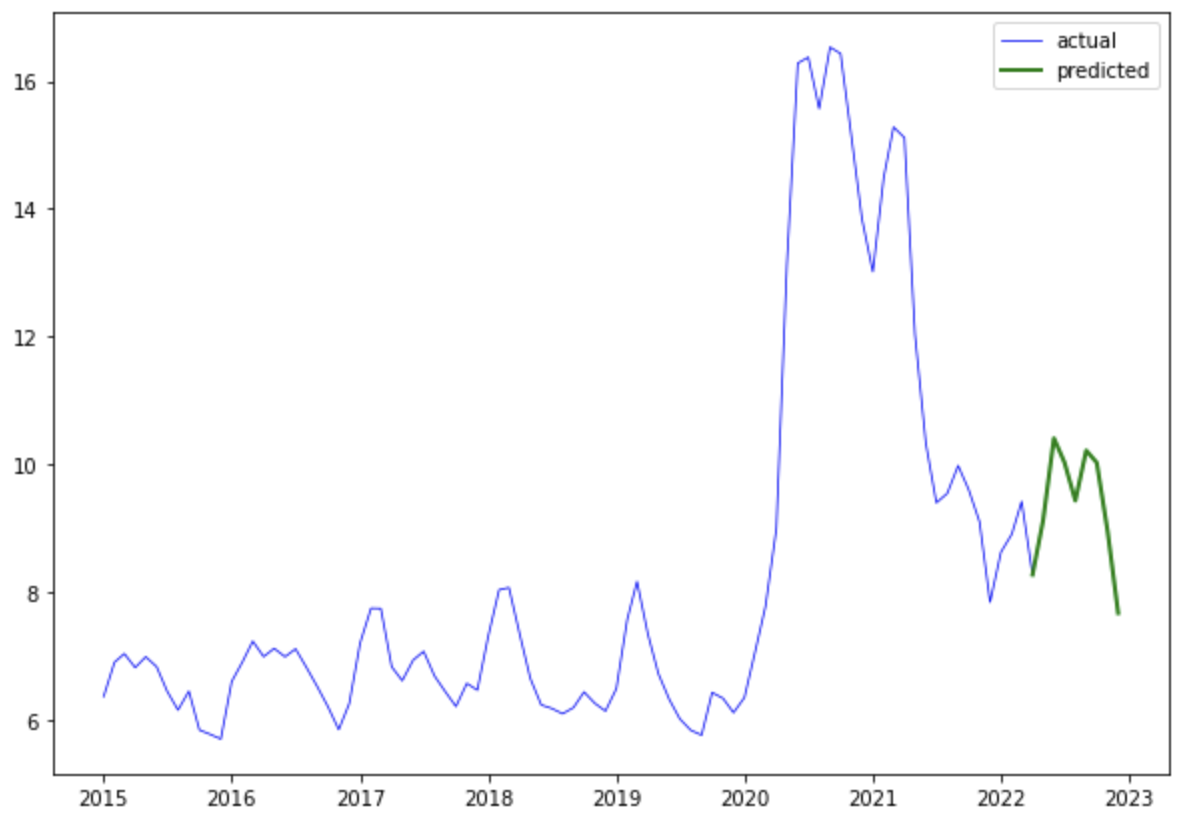
Ahora que contamos con los valores de desempleo, podemos usarlos como variables exógenas del modelo de victimización. Aplicando el método de forecast y márgenes de error, obtenemos la siguiente visualización final.
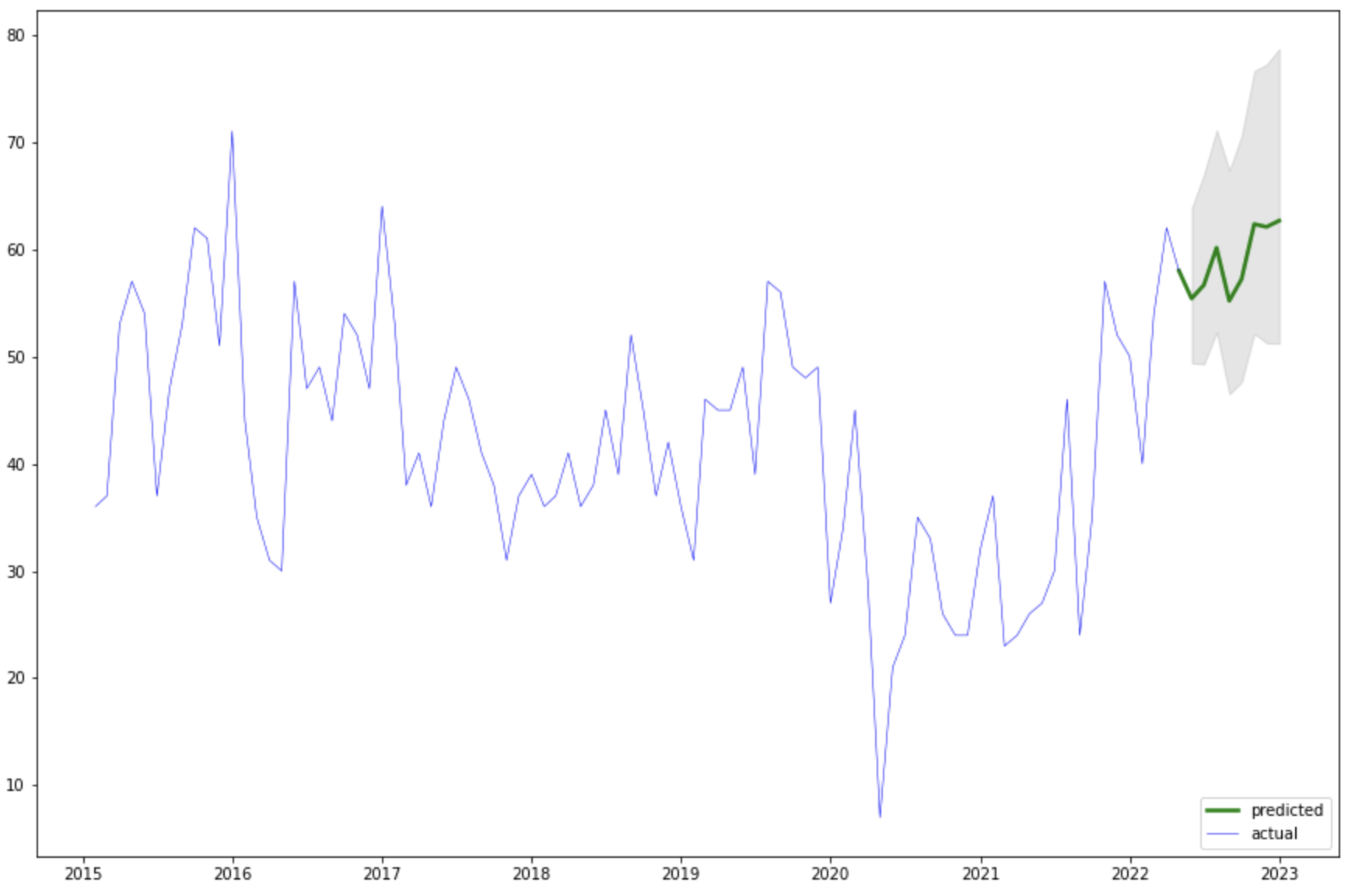
Lo cual nos indica qué, a nivel nacional, durante los próximos meses ocurrirán la siguiente cantidad de eventos de victimización a empresas.
final_model_fit.forecast(8, exog=fc).round()
# ----------------------
# | Date | Freq |
# ----------------------
# | 2022-05-01 | 55.0 |
# | 2022-06-01 | 57.0 |
# | 2022-07-01 | 60.0 |
# | 2022-08-01 | 55.0 |
# | 2022-09-01 | 57.0 |
# | 2022-10-01 | 62.0 |
# | 2022-11-01 | 62.0 |
# | 2022-12-01 | 63.0 |
# ----------------------
Podemos observar que las cifras van en aumento, superando lamentablemente los números de los últimos 4 años. Si bien existen muchos factores que afectan el grado de crimen a las empresas peruanas, la tasa de desempleo ha demostrado ser un buen indicador del aumento o disminución de la victimización. Explicar el porqué de los valores de desempleo es un tema muy interesante que involucra conocimientos de economía, política y el análisis de más fuentes de datos. Sin embargo, dicho abordaje no forma parte del alcance de este proyecto.
Conclusiones y trabajos futuros
Gracias a la metodología aplicada, se pudo predecir exitosamente el número de crímenes a empresas que podrían ocurrir en nuestro país durante el año 2022, cumpliendo el objetivo del proyecto de ciencia de datos. En cuanto a los insights, los más interesantes fueron los siguientes:
-
La determinación de las regiones con un mayor número de eventos de victimización: Si bien Lima, Piura y La Libertad son los departamentos con el mayor número de incidencias, las regiones con el mayor ratio de crimen por número de pobladores son Tumbes, Tacna y Moquegua.
-
Los tópicos más comunes de las noticias recopiladas: Las noticias pueden clasificarse dentro de 5 grandes grupos representados por 5 palabras. Además, las palabras que resaltan se interceptan con las más relevantes de los modelos bag of words y wordcloud. De entre todos estos modelos, destacan las palabras “dinero”, “comisaria”, “banda”, “tienda” y “extorsión”.
-
Mapa de calor de la geo-localización de las noticias: La elaboración de dicho mapa interactivo nos permitió apreciar la distribución geográfica de los lugares donde se presentan mas delitos contra empresas. Verificando que las zonas urbanas y céntricas son las más peligrosas para las empresas y negocios.
En cuanto a las etapas del proyecto, el uso de web scraping permitió la recopilación rápida y flexible de datos. Por otra parte, fue adecuado trabajar con python y pandas por el volumen de los datos y la sencillez de las consultas. Además, existen muchas librerías de ciencia de datos y estadística que ayudaron en el abordaje del proyecto de forma eficiente.
Como trabajos futuros, podrían probarse otros modelos de forecasting para estudiar la predicción del número de eventos de victimización a empresas, por ejemplo, modelos de machine learning supervisados y redes neuronales. En cuanto a la visualización, la elaboración de un choropleth map podría ser de gran ayuda para observar la frecuencia de crímenes por departamentos, e inclusive por provincias.
Referencias
-
Gómez, E. (2022) Course Notebooks and Slides. Universidad Católica San Pablo: Arequipa, Perú.
-
Lao, R (2018) A Beginner’s Guide to the Data Science Pipeline [online] disponible en: https://towardsdatascience.com/a-beginners-guide-to-the-data-science-pipeline-a4904b2d8ad3
-
Prabhakaran, S. (2021) ARIMA Model – Complete Guide to Time Series Forecasting in Python [online] disponible en: https://www.machinelearningplus.com/time-series/arima-model-time-series-forecasting-python/
-
Scrapy Developers (2022) Scrapy 2.6 documentation [online] disponible en: https://docs.scrapy.org/en/latest_
-
Pandas Development Team (2022) Pandas documentation [online] disponible en: https://pandas.pydata.org/docs
-
Scikit-learn developers (2022) User Guide [online] disponible en: https://scikit-learn.org/stable/user_guide.html
-
Perktold, J.; Seabold, S.; Taylor, J.; statsmodels developers (2022) User Guide [online] disponible en: https://www.statsmodels.org/stable/user-guide.html